Java MicroBenchmark Harness ile Algoritmanızın Performansını Ölçün
MicroBenchmark, birden fazla küçük uygulama birimi, algoritmalar arasındaki performans ölçümünü konu alan bir kıyaslama biçimidir. Microbenchmark ile genel olarak iş biriminin birim zamandaki yaptığı iş (througput) veya bir işin tamamlanması için geçen ortalam süre (avg time) ölçümlenmektedir.
Ölçüm Sırasında Sık Yapılan Hatalar
JVM ortamından bir iş biriminde kıyaslama (benchmark) yapılırken, genelikle System.currentTimeMillis() veya System.nanoTime() metodlarıyla ölçüm yapılma yoluna gidilir. Fakat bu biçimde yapılan ölçümler bazı sıkıntılarla karşı karşıyadır. Bu sıkıntıların bazıları JVM, bazıları ise kullanılan sistem kaynaklıdır.
Hata 1 – JIT-Compiler
Java ortamında çeşitli JVM ürünleri bulunuyor. Bunlardan en çok kullanılanı Oracle Hotspot JVM.
Hotspot JVM byte kodları koştururken Mixed mode interpretation adı verilen interpretation ve JIT (Just in Time) compile tekniklerini birlikte kullanmaktadır. JVM ayaklandığında ilk olarak interpretation tekniğiyle byte kodlar koşturulmaya başlanmaktadır. Ardından belirli bir eşikten sonra JIT devreye girerek byte kod native koda dönüştürülmekte ve uygulamada performans artışı için iyileştirme yapılmış olmaktadır.
|
JVM, JIT, Interpretation terimleri hakkında bilgilere aşağıdaki yazılardan erişebilirsiniz. |
Eğer benchmark yapmak isteyen kullanıcı, JIT derleyicisinin aktivitilerinin dorukta olduğu anlarda benchmark yapmak isterse, aslında kendi kodu ve JIT derleyicisinin aktivitilerini birlikte benchmark etmiş olur. Bu nedenle benchmark yaparken, JIT aktivitilerinin belirli bir dinginlik seviyesine (steady state) oturduğundan emin olunmalıdır.
Benchmark edilen uygulamanın dinginlik seviyesine eriştirilmesine kızıştırmak (warm up) denmektedir. Kızıştırma işleminde, benchmark edilecek iş birimi belirli bir sayıda koşturmakta, gerçek ölçüme ise kızıştırmadan sonra geçilmektedir. WarmUp işlemi JIT aktivitelerini sönümleyeceği için, gerçek kıyaslamada ölçümün doğruluğu artmış olacaktır.
JIT derleyicinin aktiviteleri -XX:+PrintCompilation JVM parametresi eklenerek gözlemlenebilir.
|
Hata 2 – JVM Optimizations
Java sanal makinesi iş parçalarını koştururken performans artışı için birçok akıllı iyileştirmeye gitmektedir. Fakat bu iyileştirmeler, benchmark işlemlerinde doğru sonuca erişmenize engel olabilmektedir. Örneğin aşağıdaki iki metodu inceleyebiliriz.
public class DeadCode {
private int n = 10;
public void methodOne(){
double result = n * Math.log(n)/2;
}
public void methodTwo(){
double result = n * Math.log(n)/2;
if(result < 0)
throw new IllegalStateException();
}
}Java Sanal Makinesi methodOne koşturduğunda, içerisindeki işlem sonucunun biryerde kullanılmadığını farkedebilir ve iyileşmeye giderek metod içerisindeki komutu işletmeyebilir.
methodTwo içindeki yapılan hesaplama sonucu ise bir sonraki satırlarda kullanıldığı için JVM’in onları koşturmama gibi bir lüksü yoktur. Bu noktada JVM bir iyileştirmeye gitmez.
Bu sebeple, benchmark yapılırken JVM optimizasyon durumları atlatılmalıdır. Aksinde ölçümlemelerde beklenmedik sonuçlar elde edebiliriz.
Hata 3 – Garbage Collector
JVM bünyesindeki Çöp toplayıcı, uygun gördüğü zamanlarda devreye girer ve aktivitesi tamamlanana kadar tüm diğer kullanıcı işlemlerini askıda tutar. Bu sebeple çöp toplayıcının devrede olduğu anlar, benchmark için sıkıntılı zamanlardır. Bu sebeple çöp toplayıcının aktiviteleri ölçüm yapan tarafından dikkate alınmalıdır.
Çöp toplayıcı aktiviteleri -XX:+PrintGCDetails JVM parametresi eklenerek gözlemlenebilir.
|
Bu gibi birçok sıkıntı veya dikkat edilmeyen noktalar benchmark ölçümlemelerinin beklenmedik sonuçlar vermesine olanak tanır. Bu sebeple benchmark işleminde bu tür sıkıntılara karşı önlem almak gereklidir.
Çözüm Yolu
Yukarıda açıklanmaya çalışılan 3 gözden kaçan nokta, microbenchmark işleminde geliştiricilerin yaptığı en sık hata biçimleridir. Bu gibi hatalara karşı en iyi çözüm yolu, bu konuda özelleştirişmiş bir microbenchmark kütüphanesini kullanmaktır. Bunlardan bazıları şunlardır; JMH, Caliper, Japex ve JUnitPerf
OpenJDK bünyesinde geliştirildiği için JMH - Java Microbenchmark Harness kullanmak bana çok daha cazip geldi.
JMH – Java Microbenchmark Harness
JMH, OpenJDK projesinin altında geliştirilen bir microbenchmarking projesidir. JMH, benchmark işlemlerinde duyulacak ihtiyaçlara ve yukarıda zikredilen sıkıntılara karşı sunduğu özel çözümlerle ortaya çıkmaktadır.
JMH, Maven veya Gradle inşa sistemleriyle birlikte çalışabilmektedir. Ayrıca çeşitli IDE’ler için eklentileri bulunmaktadır.
Örneğin JMH için hazırlanmış bir Maven projesi oluşturmak istiyorsanız aşağıdaki artifact üretici kodu kullanabilirsiniz.
mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jmh -DgroupId=org.sample -DartifactId=test -Dversion=1.0JMH ile benchmark yapılırken çeşitli notasyonlar kullanılmaktadır. Bir uygulama içerisinde kullanmadan evvel, bu notasyonlardan biraz bahsetmek iyi olabilir.
@BenchmarkMode
Bir benchmark işleminde, birim zamandaki çıktı veya bir işin aldığı zamana dayalı olarak ölçümleme yapılabilir. Hangi modda ölçüm yapılacağı @BenchmarkMode notasyonuyla belirlenebilmektedir.
Örneğin;
@BenchmarkMode(Mode.Throughput) (1)
public class App { }
// veya
@BenchmarkMode(Mode.AverageTime) (2)
public class App { }
// veya
@BenchmarkMode({Mode.AverageTime,Mode.Throughput}) (3)
public class App { }| 1 | Birim zamandaki çıktı bazlı |
| 2 | Bir işin aldığı ortalama süre bazlı |
| 3 | İkisi birden bazlı |
@OutputTimeUnit
Benchmark işleminde ölçüm sonucunun hangi zaman biriminde elde edileceği @OutputTimeUnit notasyonuyla belirlenmektedir.
Örneğin;
@OutputTimeUnit(TimeUnit.MILLISECONDS) (1)
public class App { }
// veya
@OutputTimeUnit(TimeUnit.NANOSECONDS) (2)
public class App { }
// veya
@OutputTimeUnit(TimeUnit.SECONDS) (3)
public class App { }| 1 | Çıktı milisaniye cinsinden |
| 2 | Çıktı nanosaniye cinsinden |
| 3 | Çıktı saniye cinsinden |
@Benchmark
Eğer bir metod üzerine @Benchmark notasyonu uygulanmışsa, JMH o metodu benchmark için ölçümleyecektir. Uygulanmamışsa ölçmeyecektir.
Örneğin;
@Benchmark
public void methodOne(){
// ....
}@Warmup
Benchmark uygulanacak metodu benchmark öncesinde ısındırmak için belirli bir iterasyonda çalıştırmaktadır. Isındırma işlemi JIT derleyicisinin aktivitelerinin sönümlenmesi için uygulanmaktadır.
Örneğin;
@Benchmark
@Warmup (1)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Warmup(iterations = 10) (2)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Warmup(iterations = 10,time = 5,timeUnit = TimeUnit.SECONDS) (3)
public void methodOne(){
// ....
}| 1 | 20 kere ısındırma iterasyonu uygular. Herbir iterasyonu 1 saniye boyunca uygular. |
| 2 | 10 kere ısındırma iterasyonu uygular. Herbir iterasyonu 1 saniye boyunca uygular. |
| 3 | 10 kere ısındırma iterasyonu uygular. Herbir iterasyonu 5 saniye boyunca uygular. |
@Measurement
@Warmup gibidir. @Warmup ısındırma işlemi yaparken, @Measurement gerçek ölçüm işlemi yapar. Yani ölçümü sonuca katar.
Örneğin;
@Benchmark
@Measurement (1)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Measurement(iterations = 10) (2)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Measurement(iterations = 10,time = 5,timeUnit = TimeUnit.SECONDS) (3)
public void methodOne(){
// ....
}| 1 | 20 kere ölçüm iterasyonu uygular. Herbir iterasyonu 1 saniye boyunca uygular. |
| 2 | 10 kere ölçüm iterasyonu uygular. Herbir iterasyonu 1 saniye boyunca uygular. |
| 3 | 10 kere ölçüm iterasyonu uygular. Herbir iterasyonu 5 saniye boyunca uygular. |
@Fork
Bir metod üzerinde ölçüm yapılacakken genelde sadece tek bir JVM üzerinde ölçümleme yapılmaktadır. Fakat microbenchmark işleminde birden fazla JVM üzerinde tekrar tekrar ölçüm yapmak ve sonuçların ortalamasını almak, ölçümün keskinliğini artırır.
@Fork notasyonu benchmark yapılacak metodun kaç JVM üzerinde sınanacağını belirlemektedir. Belirlenen fork sayısı kadar JVM, sıra sıra olarak JMH tarafından oluşturularak ölçüm yapılmaktadır.
Örneğin;
@Benchmark
@Fork(value = 1) (1)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Fork(value = 5) (2)
public void methodOne(){
// ....
}| 1 | Tek bir JVM ile ısındırma/ölçümleme yapılır. |
| 2 | 5 JVM ile ısındırma/ölçümleme yapılır. |
@Threads
Benchmark uygulanacak metodun aynı anda kaç Thread ile koşturulacağı @Threads notasyonuyla belirlenebilmektedir. Böylece Thread sayısının ölçüme olan etkisi kıyaslanmış olmaktadır.
Örneğin;
@Benchmark
@Threads(value = 1) (1)
public void methodOne(){
// ....
}
// veya
@Benchmark
@Threads(value = 16) (2)
public void methodTwo(){
// ....
}| 1 | 1 iş parçacığı ile benchmark yapılır. |
| 2 | 16 iş parçacığı ile benchmark yapılır. |
@Group
Birden fazla benchmark metodunu tek bir grup olarak işaretler. Benchmark sonucunda aynı gruptaki benchmark metodlarından elde edilen sonuçların ortalaması da ilave olarak bildirilir.
Örneğin;
@Benchmark
@Group(value = "kodcu") (1)
public void methodOne(){
// ....
}
@Benchmark
@Group(value = "kodcu") (2)
public void methodTwo(){
// ....
}
@Benchmark (3)
public void methodThree(){
// ....
}| 1 | kodcu grubundan bir benchmark metodu |
| 2 | kodcu grubundan bir benchmark metodu |
| 3 | Tekil bir benchmark metodu |
@OperationsPerInvocation
Bazı zamanlarda ölçümlemek istediğimiz iş parçası, aynı işi tekrar tekrar koşturabilmektedir. Eğer tekrarlı işlerden tek bir tekrarına dair benchmark çıktısı almak istiyorsak @OperationsPerInvocation notasyonunu kullanabiliriz.
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.Throughput)
public class App {
@Benchmark
@OperationsPerInvocation(value = 2000) / (1)
public void methodOne(){
for(int i = 0 ;i<2000;i++){
// Some work
}
}
}Örneğin yukarıdaki benchmark metodu içindeki Some work operasyonu 2000 kere tekrarlanacaktır, 2000 yerine 1 tekrarın Throughput’unun ne kadar olduğunu öğrenmek istersek (1) numaradaki kullanımda olduğu gibi 2000 değerini girebiliriz.
@State
Benchmark uygulanan sınıfta bulunan global alanların, benchmark metod, grup ve threadlerinin ne derece paylaşacağını belirler.
Örneğin;
@State(value = Scope.Benchmark) (1)
public class App { }
@State(value = Scope.Group) (2)
public class App { }
@State(value = Scope.Thread) (3)
public class App { }| 1 | Bir benchmark metodu koşturulurken aynı global alanlar paylaşımlı olarak erişilir. |
| 2 | Aynı gruptaki benchmark metodları koşturulurken aynı global alanlara paylaşımlı erişilir. |
| 3 | Bir thread boyunca aynı global alanlar paylaşımlı olarak erişilir. |
@Setup
Başlangıç aşamasında yapılması gereken işler @Setup notasyonuna sahip metod ile koşturulur.
Örnek 1;
@State(Scope.Benchmark) (1)
public class App {
private int counter;
@Setup(Level.Trial) (2)
public void init(){
counter = 0;
}
...
}| 1 | Benchmark Scope. |
| 2 | Her benchmark metodu çalıştırılmadan önce init metodunu bir kez çalıştırır. Böylece global alandaki counter sıfırlanmış olur. Birden fazla thread olsa bile aynı counter değerine paylaşımlı erişir. |
Örnek 2;
@State(Scope.Thread) (1)
public class App {
private int counter;
@Setup(Level.Trial) (2)
public void init(){
counter = 0;
}
...
}| 1 | Thread Scope. |
| 2 | Bir benchmark metodu koşturulmaya başladan evvel, kaç thread ile ölçüm yapılacaksa, o sayıda init metodu koşturulur. counter alanı her bir thread için izole olmuş, ayrı tutulmuş olur. |
Örnek 3;
@State(Scope.Benchmark) (1)
public class App {
private int counter;
@Setup(Level.Iteration) (2)
public void init(){
counter = 0;
}
...
}| 1 | Benchmark Scope. |
| 2 | Her bir ısındırma (warmup) ve ölçüm (measurement) döngüsü başlamadan evvel init metodu koşturulur. Benchmark metodunun sahip olduğu iş parçacıkları herbir iterasyon için paylaşımlı olarak aynı counter alanına erişir. |
Örnek 4;
@State(Scope.Thread) (1)
public class App {
private int counter;
@Setup(Level.Iteration) (2)
public void init(){
counter = 0;
}
...
}| 1 | Thread Scope. |
| 2 | Her bir ısındırma (warmup) ve ölçüm (measurement) döngüsü başlamadan evvel init metodu koşturulur. Benchmark metodunun sahip olduğu iş parçacıkları herbir iterasyon için izole olarak kendilerine özel bir counter alanına erişir. |
Örnek 5;
@State(Scope.Group) (1)
public class App {
private int counter;
@Setup(Level.Trial) (2)
public void init(){
counter = 0;
}
...
}| 1 | Group Scope. |
| 2 | Aynı gruptaki benchmark metodları çalıştırılmadan önce bir kere init metodu çalıştırır (Grup başına bir kez). Birden fazla thread olsa bile aynı grup metodları aynı counter değerine paylaşımlı erişir. |
@TearDown
Sonlandırma aşamasında yapılması gereken işler @TearDown notasyonuna sahip metod ile koşturulur. @Setup benchmark veya iterasyon öncesi çalıştırılırken, @TearDown benchmark veya iterasyon sonrası çalıştırılır. @TearDown notasyonu, @Setup notasyonu gibi ayrı bir metodda yapılandırılmaktadır.
Uygulama Zamanı
Java ortamında Map türünden nesnelerin eş zamanlı olarak çalışan iş parçacıklara karşı Thread-Safe davranması için çeşitli özel Map nesneleri bulunmaktadır. Hashtable, ConcurrentHashMap ve SyncronizedMap bunların en çok bilinen örnekleridir.
Bu uygulamada ise ConcurrentHashMap ve Syncronized Map implementasyonlarının artalan Thread sayısına karşı performans karşılaştırması yapılmak istenmektedir. Yapılacak kıyaslama, 1-8 arası iş parçacığının birim zamandaki operasyon sayısı (Throughput) bazında put operasyonunu sınamaktadır.
Sistem Bilgileri
Benchmark işlemi aşağıdaki makine üzerinde gerçekleştirilmiştir.
-
Intel i5-3210 M 2.50 GHz (4 Core)
-
8 GB Memory
-
64 Bit Windows 7 OS
-
JDK 1.8
@OutputTimeUnit(TimeUnit.SECONDS)
@BenchmarkMode({Mode.Throughput})
@State(Scope.Benchmark)
public class MapPutter {
private Map<Integer, Integer> synchronizedMap;
private Map<Integer, Integer> concurrentMap;
private static final int N = 2_000_000;
private static final int THREAD_COUNT = 8;
private static final int ITERATION_COUNT = 10;
private static final int WARMUP_COUNT = 10;
private static final int FORK_COUNT = 3;
@Setup(Level.Trial)
public void init() {
synchronizedMap = Collections.synchronizedMap(new HashMap<>(N)); (1)
concurrentMap = new ConcurrentHashMap<>(N); (2)
}
@Benchmark (3)
@Fork(value = FORK_COUNT) (4)
@Warmup(iterations = WARMUP_COUNT) (5)
@Measurement(iterations = ITERATION_COUNT) (6)
// @Threads(value = 16)
public Integer synchronizedPut() {
int key = ThreadLocalRandom.current().nextInt(1, N); (7)
int value = ThreadLocalRandom.current().nextInt(1, N); (8)
Integer result = synchronizedMap.put(key, value); (9)
return result;
}
@Benchmark
@Fork(value = FORK_COUNT)
@Warmup(iterations = WARMUP_COUNT)
@Measurement(iterations = ITERATION_COUNT)
// @Threads(value = 16)
public Integer concurrentPut() {
int key = ThreadLocalRandom.current().nextInt(1, N);
int value = ThreadLocalRandom.current().nextInt(1, N);
Integer result = concurrentMap.put(key, value);
return result;
}
public static void main(String[] args) {
int[] threadCounts = new int[]{1,2,3,4,5,6,7,8}; (10)
for (int threadCount : threadCounts) {
Options opt = new OptionsBuilder()
.include(MapPutter.class.getSimpleName()) (11)
.threads(threadCount) (12)
.build();
new Runner(opt).run(); (13)
}
}
}| 1 | Synchronized Map nesnesi oluşturuluyor. |
| 2 | ConcurrentHashMap nesnesi oluşturuluyor. |
| 3 | Metod benchmark için işaretleniyor. |
| 4 | 3 farklı JVM’de ölçüm yapılacağı belirleniyor. |
| 5 | Kızıştırma iterasyonu 10 olarak belirleniyor. |
| 6 | Ölçme iterasyonu 10 olarak belirleniyor. |
| 7 | Key için, 1-2 milyon arasında rastgele değer üretiliyor. |
| 8 | Value için, 1-2 milyon arasında rastgele değer üretiliyor. |
| 9 | Key ve Value değerleri Map nesnesine put ediliyor. |
| 10 | 1-8 arası iş parçacıklarında ölçüm yapılacak |
| 11 | Ölçüm yapılacak sınıf seçiliyor |
| 12 | Kaç Thread kullanılacağı dinamik olarak belirtiliyor. |
| 13 | Tanımlı ayarlara göre benchmark koşturuluyor. |
Uygulama Sonucu
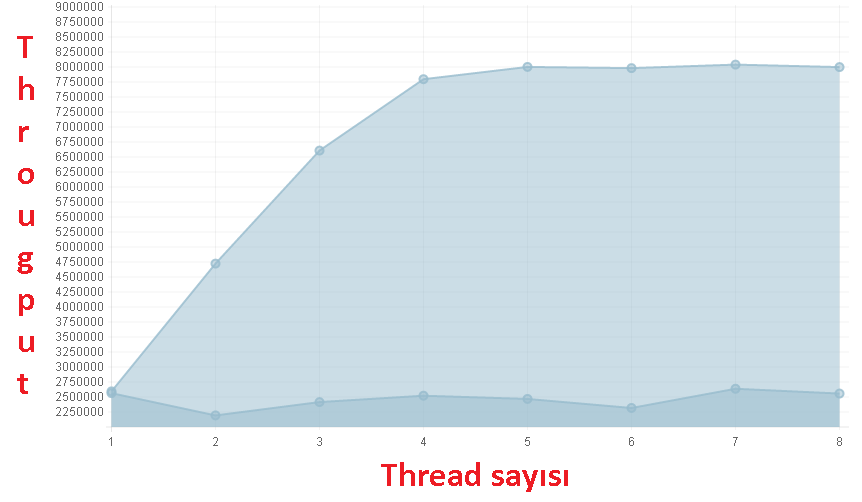
Thread sayısı arttığında, birim zamandaki operasyon sayısı (Throughput)’a etkisi aşağıdaki grafikte olduğu gibidir. JMH’in ürettiği çıktıya ise buradaki bağlantıdan erişebilirsiniz.
Değerlendirme
SynchronizedMap, Thread sayısı istediği kadar artarsa artsın t anında tek bir iş yapabilir. Çünkü tüm metodları synchronized keywordü ile işaretlenmiştir. Grafik üzerinden bakıldığında, SynchronizedMap için put operasyonunun artalan Thread sayısına karşı hemen hemen sabit seyrüsefer yaptığı gözlemlenebilir.
ConcurrentHashMap, artalan Thread sayısına karşı t anında N tane yazma operasyonu yapabilir.
N şunlara bağlıdır;
-
ConcurrentHashMap#concurrencyLevelalanı. Bu değer varsayılan olarak 16‘dır ve ConcurrentHashMap yapılandırıcısı üzerinden değiştirilebilir. Bu şu demektir, t anında 16’ya kadar yazma operasyonu yapabilir. Fakat işlemcinizin en azından 16 çekirdekli olması gereklidir. -
Eğer CPU sayınız 16’dan küçük ise N CPU çekirdek sayınız kadardır. Bu benchmark işleminin yapıldığı işlemci 4 çekirdekli olduğu için, eş zamanlı olarak 4 operasyon yapılabileceği sonucunu çıkarabiliriz.
Grafikten de anlaşılacağı üzere, Thread sayısı 1-4 iken Throughput hemen hemen lineer olarak artmış, 4’den büyük durumlarda ise hemen hemen sabit kalmıştır.
Uygulamaya https://github.com/rahmanusta/jmh-samples üzerinden erişebilirsiniz.
Tekrar görüşmek dileğiyle..
Tag:backend, benchmark, performans, profiler
You may also like
Swagger Nedir? Neden kullanılır?
Spring CLI ile Spring Boot Projeleri Hazırlamak
3 Comments
Güzle yazoı