Apache Tika : Dosya tipi nasıl tespit edilir?
Bugün sizlere bir Apache projesi olan Tika‘ dan bahsetmek istiyorum. Apache Tika, dosya sisteminde veya bellek ortamında bulunan verilerin/dosyaların içerik tipini elde etmeyi amaçlayan bir Apache vakfı projesidir.
Tika, dosya sistemi veya anabellekte bulunan verilerin veri tiplerini elde etmeye yararken, aynı zamanda bu veri ve dosya tiplerine dair çeşitli metadata verilerini de sunmaktadır.
Tika’ yı uygulamalarınızda kullanmak için aşağıdaki Maven dependeny tanımlamalarını kullanabileceğiniz gibi, komut sistemi üzerinden de bu işlemleri gerçekleştirebilirsiniz.
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.4</version>
</dependency>
Örnek uygulama
Tika ile bir dosya veya veri kümesinden tip tespit edebilmek için Tika isimli sınıf kullanılabilmektedir. Tika sınıfının aşırı yüklenmiş detect metodu, içerik tipini tespit etmektedir.
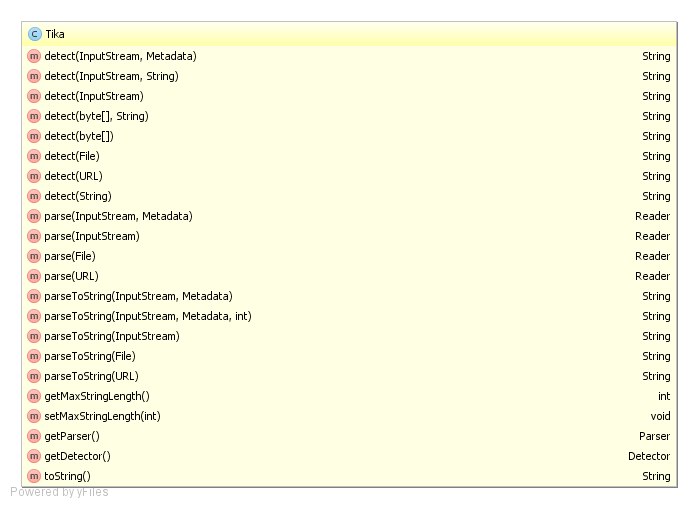
Tika#detect metodu, File, byte[], InputStream, URL, String nesneleriyle tanımlı veri kaynaklarını tipini tespit edebilmektedir.
Uygulama
public class App {
public static void main(String[] args) throws Exception {
String root = "./src/main/resources";
Tika tika = new Tika();
/// File nesnesinden tipi tespit eder.
File file = new File(root + "/javaee7.jpg");
String tip = tika.detect(file);
System.out.println("Jpg İçeriği : " + tip);
/// InputStream nesnesinden tipi tespit eder.
FileInputStream is = new FileInputStream(root + "/index.php");
System.out.println("Php içeriği : " + tika.detect(is));
/// byte[] dizi nesnesi üzerinden tipi tespit eder.
try (FileChannel kanal =
FileChannel.open(Paths.get(root + "/tika.png"), READ)) {
ByteBuffer tampon = ByteBuffer.allocate((int) kanal.size());
kanal.read(tampon);
System.out.println("Png içeriği : " + tika.detect(tampon.array()));
}
/// PDFParser nesnesi üzerinden Metadata bilgilerini elde eder.
Metadata metadata = new Metadata();
ContentHandler handler = new DefaultHandler();
Parser parser = new PDFParser();
ParseContext context = new ParseContext();
parser.parse(new FileInputStream(root + "/mypdf.pdf"),
handler,
metadata,
context);
String[] names = metadata.names();
for (String name : names)
System.out.printf("%s : %s %n", name, metadata.get(name));
}
}
Uygulama çıktısı
Jpg İçeriği : image/jpeg Php içeriği : text/x-php Png içeriği : image/png dcterms:modified : 2013-12-17T17:55:09Z meta:creation-date : 2013-12-17T17:54:44Z meta:save-date : 2013-12-17T17:55:09Z dc:creator : usta Last-Modified : 2013-12-17T17:55:09Z Author : usta dcterms:created : 2013-12-17T17:54:44Z SourceModified : D:20131217175423 date : 2013-12-17T17:55:09Z modified : 2013-12-17T17:55:09Z creator : usta xmpTPg:NPages : 1 Creation-Date : 2013-12-17T17:54:44Z meta:author : usta created : Tue Dec 17 19:54:44 EET 2013 producer : Adobe PDF Library 10.0 Company : Content-Type : application/pdf xmp:CreatorTool : Acrobat PDFMaker 10.0 for Word Last-Save-Date : 2013-12-17T17:55:09Z
Apache Tika’ nın tanıyabileceği tipleri bu bağlantıdan erişebilirsiniz.
Örnek uygulamaya ise bu bağlantıdan erişebilirsiniz.
Tekrar görüşmek dileğiyle.
You may also like
Swagger Nedir? Neden kullanılır?
Spring CLI ile Spring Boot Projeleri Hazırlamak